故事
最近花了半個月的時間開發了 go-linebot,是一款能夠在 line 上面進行圍棋對弈,以及串接 KataGo 進行 AI 對弈和 AI 覆盤的服務
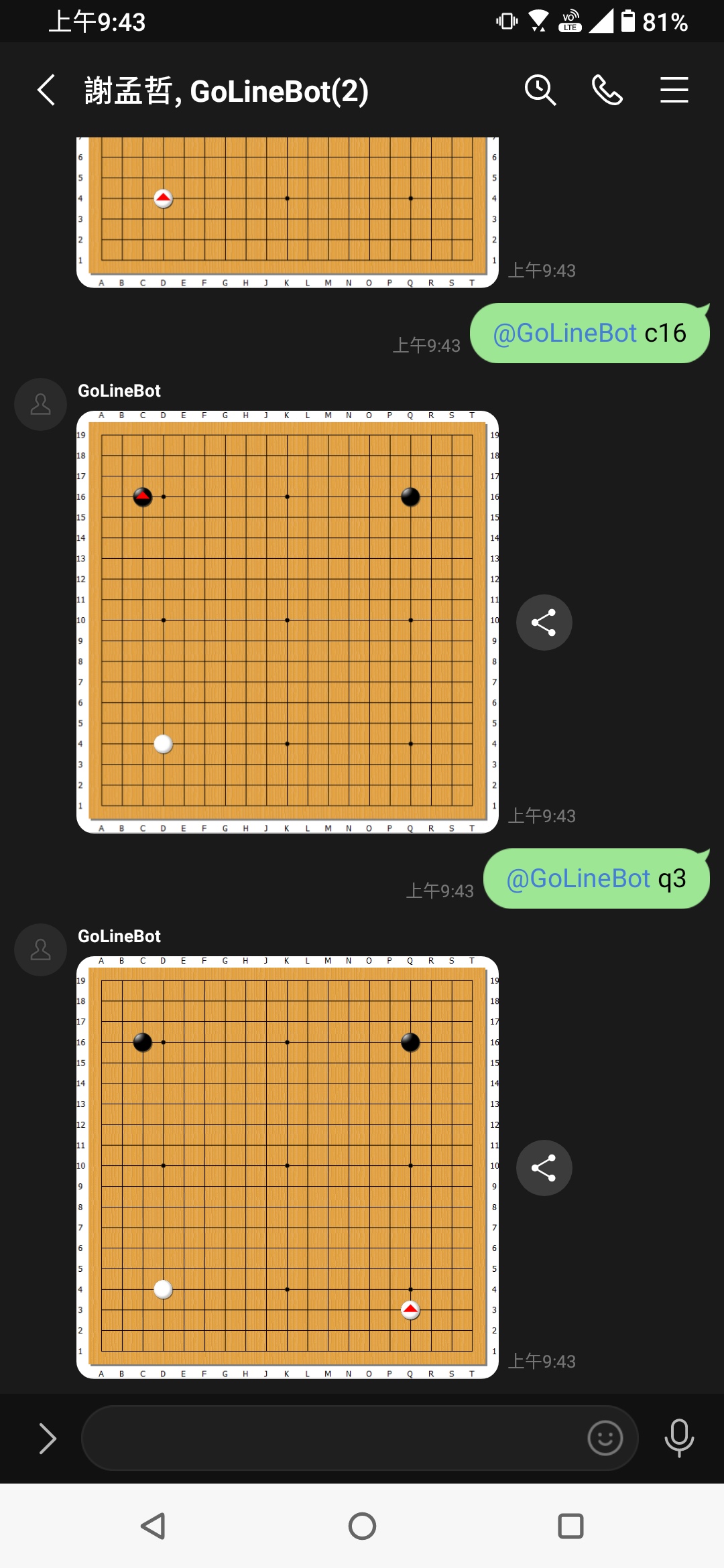
一開始是徐老師在圍棋社的群組裡寫了一個 @NTUGoBot 的 line 機器人,只要輸入 “@NTUGoBot 棋盤座標” 就會自動回傳一張下棋後的全盤圖片,一群三十幾歲的社畜們不像以前可以隨時坐在社辦裡一天下個兩三盤棋,改成在 line 上面的非即時對弈反而可以輕鬆的享受下棋的樂趣
徐老師身為中文系畢業的文組學生竟然用 AI 就可以寫出這完整的下棋系統,包括下子不能下到同一個位置、劫爭的邏輯等等實在是太強了!第一盤棋是所有人隨興的下,任何人有空的時候都可以當黑、白方去下棋,下到最後覆盤才發現這盤棋的勝負一直變來變去的,此時我想到可以用 katago 當作 AI 的分析引擎,將整盤的手順餵進去應該就可以在下完棋後,馬上看到是哪幾手棋下得好、下的錯導致局面崩盤,這樣似乎蠻有趣的~
於是就開始動手了,一開始先把 linebot 的架構弄出來,由於比較熟悉 javascript 所以採用的是 node.js,接著需要將 .sgf 的棋譜檔案傳入 katago 中,將每一步分析出的好壞篩選後再回傳到 line,這時候就遇到第一個大問題了,前面請 AI 弄出一個 linebot 的架構非常快,基本上也不需要改什麼,接著要他將 sgf 檔案傳給 katago 分析時,AI 一直叫我在 katago 的設定檔 default_analysis.cfg 中添加 sgfFile 的參數指向 sgf 檔案的所在位置,我在這邊卡了很久一直修改,途中問了 Gemini, ChatGPT 等都是同樣叫我用 sgfFile 的參數讓 katago 去讀取棋譜檔案,改了許久加上我去 katago 官網仔細看完設定檔的各種參數後,才發現根本就沒有一個叫做 sgfFile 的參數可以讓他自動讀取棋譜檔案!完全被 AI 的幻覺騙了,而且兩個都講出同樣的解法讓我鬼打牆了更久,後續查了一下才知道需要將棋譜檔案解析出來成每一步的座標 (D4, R5 等) 依序傳給 katago,他才有辦法做出最後的分析結果,剛好找到了 katawrap 這個可以將 sgf 傳入給 katago 的套件直接拿來用,太好了第一個大難關終於解決了,成功執行 katago analysis 的指令將整盤的分析結果求出來了!
接著思考分析出來的結果要怎麼呈現呢?一開始是打算挑出目數損失最大的前 20 手秀在 line 上面,以及需要顯示 AI 建議的 PV(Principal Variation) gif 動態圖,要怎麼畫出幾步棋的 gif 動圖後回傳到 line 上面呢? AI 建議用到 pillow, imageio 這些 python 套件去做處理,而不建議用 node.js 的 canvas 方式畫圖,原因是 python 生態系就是擅長畫圖的,而 node.js 主要是拿來做 api, server 端的處理,於是咻咻咻,AI 很快的就把畫圖的功能實作出來了
此時我發現這樣架構太亂了,畫圖跟 katago 分析使用的是 python 而 linebot 路由是使用 node.js,node.js 需要用一串複雜的程式去呼叫 python,於是心一橫想說趁著專案還沒有太大前,請 AI 將 node.js 的所有程式碼都改成 python 處理,沒想到只用了大約兩、三個小時 AI 就把原先 node.js express 的邏輯完整改到 python fastapi 去了,邏輯完全沒變,太完美了!沒想到叫 AI 重構這麼強
後面想說冷冰冰的分析數字,每一手棋的目差損失、勝率等等似乎有點太單調了,所以打算調用 LLM api 餵入 20 筆關鍵手的資料讓他用人話的方式說出有趣的評論,一開始想試用最近看到比較便宜的 Minimax 2.1,實際註冊登入後發現國際版一次儲值就要大約 $25 美金,不想要第一次就儲值這麼多,畢竟是個 side project 還不知道之後做出來感覺如何、會不會一直用下去,於是最終決定用 ChatGPT 先儲值 $5 美金試試,一次呼叫 LLM 評論還不到 0.2 塊台幣,足夠我不斷嘗試玩玩看了
在 tune 過一輪餵入 ChatGPT 的 prompt 後,可以運行的最小版本終於出來了!一切都用 cloudflare tunnel 在本機電腦起 https 服務,linebot 打到 /webhook 的路由後讀取使用者最新在 line 上傳的 sgf 檔案餵入給 katago 分析,將分析後的結果挑出 20 筆,畫出這 20 筆 AI 推薦的主要變化 PV,再搭配 LLM 評論,看起來是個完整的東西了!
靠著這時代 AI 的強大,初步的版本只花了一週的時間,終於可以分享到群組中看看響應如何了,開心的申請另一個 linebot: @NTUGoAnalysis,希望執行 “@NTUGoAnalysis 覆盤” 指令就可以執行上面那一串的流程,但… 當我打算把 @NTUGoAnalysis 加入群組時,不知道為什麼一直加不進去,後來查了一下才發現 line 竟然規定一個群組只能有一個官方帳號的 linebot 存在,什麼!那這樣我做的覆盤功能跟原本的下棋功能不就不能一起運行了嗎?後來真的找不到可以突破這個規定的方式,只好去問徐老師拿到他寫的下棋功能原始碼,接著把下棋功能跟覆盤功能一起整併進來,還記得那時想說弄了一個禮拜好不容易有了覆盤功能可以休息了,結果被 line 官方的限制一搞,又要再花時間把下棋功能一起整進來了…
靠著 AI 整合進徐老師的程式碼幾乎是一步到位,但由於答應了徐老師要把整個下棋功能搬到雲端,這樣才不會本地電腦關機或休眠時,大家就無法下棋了。在跟 AI 討論整體架構後,下一步打算把 linebot 的功能搬到 gcp cloud run 上,cloud run 只在接收到 /webhook 的呼叫時才會開機運行服務,以我們自己想要下棋的小流量來看,這樣的架構做到完全免費應該不是問題
接著申請一個新的 gcp 帳號,然後處理 env, secret 等環境變數的問題,還有使用者上傳的棋譜以及每一步下棋後回傳的棋盤圖片需要存儲到 gcs 上面,靠著 AI 跌跌撞撞地處理一堆雜事,最終弄出了一個 ./scripts/deploy.sh 檔案可以一鍵上傳更新程式碼到 cloud run 上面了,此時的 linebot 是部署在 gcp 上面,而 katago 功能還是部署在本機環境,當 katago 分析跑完後會在送回 callback 給 gcp linebot 通知完成,接續跑 LLM 評論跟畫圖回傳回去
到目前為止已經有了兩種架構,一個是最初把所有東西都放在本機跑,而另一個是把 linebot 功能部署在 gcp 以讓下棋功能可以整天運作,但現在我的程式碼看起來已經很混亂了,雖然跑得起來但感覺很多功能都散在各處,於是此時決定至少把不同架構放在不同的資料夾分別是本地運作的 localhost_all 跟布在 gcp 上的 gcp_linebot_localhost_katago
既然都把 linebot 部署在 gcp 上了,就希望讓 katago 分析也部署在雲端,這樣覆盤功能也可以隨時運作了~ 而且現在我本機 Mac M2 運行 katago 覆一盤棋約需要十分鐘似乎有點久,之後利用雲端 GPU 的運算資源肯定可以縮短不小時間,剛好看到有一個叫做 Modal 的運算平台,佛心的是他竟然免費提供每個月 $30 塊美金的運算資源,對於我這個小小 side project 來說真是太適合了,於是開始著手將 katago 搬遷到上面去
將 katago 部署到 modal 上面真是困難重重,首先或許是 Modal 是一個新興的平台,其 api 串接已經改版了好幾次,請 AI 產生程式碼後常常跳出函式不存在的問題,需要一步步排解,另外最重大的困難是如何在 Modal 上面安裝好一個可以運行的 katago,這部分用到了一些 docker 相關的知識還需要寫一堆 script 程式碼將必須的套件安裝上去,在不知道踩了多少坑之後,突然看到成功部署上去的 log 真是令人感動!而這也就是最終全部上雲的版本 gcp_linebot_modal_katago,此時 AI 覆盤也只需要大約 5 分鐘就可以跑完了
目前為止終於把想做的事情做到一個段落了!時間已經過去了兩個禮拜真是累,隔天馬上跟徐老師確認他下棋功能搬到雲端後是否正常運作,結果發現了一個小 bug,那就是手機版的 line 是可以提及 “@NTUGoBot” 官方帳號的,但電腦版的 line 不知道為什麼只能提及人而無法提及官方帳號… 之前有很多人都是用電腦版的 line 下棋比較方便,所以還需要做一點小修改,將單純的 “@NTUGoBot” 文字也要提取出來,並執行後面的指令
之後終於將 NTUGoBot 加入到群組中了,覆盤功能我覺得看起來是蠻酷的,但不知道是不是 AI 太強分析出來的 PV 變化幾乎都令人看不太懂 XD 但可以知道哪幾步棋的下法造成勝率大幅變化還是蠻好玩的,而且最後額外做的全盤勝率變化圖也可以看出整盤的優勢是如何 90% => 50% => 3% => 70%,這樣跳動改變的
試用過覆盤功能後的王博士提出了一個新的需求 - AI 對下,原因是有些局部太複雜、或是最近流行的 AI 大型定石,根本不知道要如何下才是正確的手順,如果讓 AI 來下的話或許就可以了解這個局部的最佳下法,拜之前花許多時間將 katago 部署到 modal 上的努力,進一步實作出 AI 對弈的功能只花費了一天,當初覆盤用的是 katago analysis 而現在要讓 AI 下下一手是使用 katago gtp 讀取 katago 輸出的座標再畫回去棋盤上就可以了
開發中遇到的難題
1. katago sgfFile 參數錯誤
一開始打算要將 .sgf 圍棋檔案餵進 katago,照著 AI 的指示在 katago 的設定檔中用了 sgfFile 參數傳入 .sgf 檔案的路徑位置,在這邊鬼打牆了許久後來才發現 AI 根本都在亂說,katago 的設定檔並沒有一個叫做 sgfFile 參數的東西,後來是靠著 katawrap 套件才成功把 .sgf 檔案轉成每一手的座標位置後再餵入 katago 中做分析
2. node.js 重構成 python
由於我只會寫 javascript,所以一開始採用了 node.js 去實作 linebot 路由,但當要將 katago 分析的結果畫成圖片回傳時,AI 建議使用 python 中的 pillow, imageio 等套件,會比直接在 node.js 中畫圖輕鬆許多,加上此時 katawrap 也是用 python 撰寫的,所以想說該是時機把 linebot 路由直接重構成 python 維持整體程式碼的架構了,幸運的是 AI 似乎很擅長這部分,一句話幾乎就把原有的 node.js 依賴全部移除改用 python 的 fastapi 套件去實作路由
3. 部署到 gcp 上後,畫棋的順序不對
這個問題大概分成兩點:
- 下第二手棋時,第一手棋在圖上會消失不見
- 第一手棋是黑棋,下第二手棋時卻還是一樣畫黑棋上去
是一個莫名其妙的 bug,一開始遇到時覺得是不是 AI 在畫每一手的計算的邏輯出錯,所以請 AI 檢查了很多遍,後來怎麼查也查不出有問題的地方,debug 了很久才發現是因為當下下棋的狀態是存在 gcs 上,一個叫做 state.json 的檔案,裡面的格式像這樣:
1 | { |
而當下這局 “game_id” 的狀態也是存在 gcs 中的某個 .sgf 檔案 (ex. game_12345.sgf),在畫棋的時候會抓出這兩個檔案先判斷這一手棋是黑棋或白棋後把新的一手棋畫在棋盤上,最後更新 .sgf 檔案
而問題就出在 gcs 預設會快取檔案,所以當抓取 .sgf 檔案及 state.json 檔案的時候抓到的是舊的快取版本,導致原本這一手應該要是白棋的卻以為是黑棋畫上去,後續再更新這兩個檔案的時候加上 cache_control: "no-cache, max-age=0" 後終於解決了!
4. modal 安裝 katago 問題
4-1. –appimage-extract
1 | "wget -q https://github.com/lightvector/KataGo/releases/download/v1.16.4/katago-v1.16.4-cuda12.1-cudnn8.9.7-linux-x64.zip -O /tmp/katago.zip || true", |
一開始需要在 modal 的 docker 環境中下載 katago 並將其解壓縮,但馬上就遇到了以下問題:
1 | Error: No suitable fusermount binary found on the $PATH Error: $FUSERMOUNT_PROG not set open dir error: No such file or directory |
之後又在 Gemini 跟 ChatGPT 鬼打牆了一陣子才使用 --appimage-extract 的參數解決這個安裝問題
4-2. apt-get install 卡住
1 | Please select the geographic area in which you live. Subsequent configuration |
執行 apt-get install 的時候會卡在這個訊息,查詢 AI 後說是要安裝套件時關閉互動模式選項,嘗試設定了 ENV DEBIAN_FRONTEND=noninteractive 這個環境變數卻一直沒有效果,後來才發現是 modal api 寫法的問題,需要用 .env 寫法使得環境變數可以讓後面的 .apt_install 吃到
1 | image = ( |
4-3. python 執行環境指向問題
在本機開發時,執行 katawrap 所使用的 python 執行環境是自己用 virtual env 建出來的,所以運行指令類似這樣
1 | VENV_PY="${VENV_PY:-venv/bin/python}" |
而在部署到 modal 上時,並沒有 virtual env 環境,取而代之的是直接用 system 的 python 執行,再問了 AI 多次嘗試後才知道可以用 sys.executable 這個寫法取得 python 的執行環境而解決這個問題
1 | os.environ["VENV_PY"] = sys.executable |
Katago benchmark
將 katago 部署到 modal 上時需要挑選用哪個 GPU,所以以下測試了幾種不同 GPU 搭配 katago 不同的設定檔參數做了一些 benchmark 的測試,最終結果是 L4 GPU 的性價比最高
第 1 組 katago 參數
nnCacheSizePowerOfTwo = 23
nnMaxBatchSize = 128
nnMutexPoolSizePowerOfTwo = 17
nnRandomize = true
numAnalysisThreads = 32
numSearchThreads = 1
gpu=”T4”
visits: 100 01:17 = 0.000164 x 77 = 0.012628
visits: 400 04:33 = 0.000164 x 273 = 0.044772
gpu=”L4” (win!)
visits: 100 00:46 = 0.000222 x 46 = 0.010212
visits: 400 02:10 = 0.000222 x 130 = 0.028860
gpu=”A10”
visits: 100 00:39 = 0.000306 x 39 = 0.011934
visits: 400 02:16 = 0.000306 x 136 = 0.041616
gpu=”A100”
visits: 100 00:31 = 0.000583 x 31 = 0.018073
第 2 組 katago 參數
nnCacheSizePowerOfTwo = 23
nnMaxBatchSize = 256
nnMutexPoolSizePowerOfTwo = 17
nnRandomize = true
numAnalysisThreads = 1
numSearchThreads = 16
gpu=”L4”
visits: 100 01:09 = 0.000222 x 69 = 0.015318
visits: 400 02:31 = 0.000222 x 151 = 0.033522
第 3 組 katago 參數
nnCacheSizePowerOfTwo = 23
nnMaxBatchSize = 512
nnMutexPoolSizePowerOfTwo = 17
nnRandomize = true
numAnalysisThreads = 64
numSearchThreads = 1
gpu=”L4”
visits: 400 02:31 = 0.000222 x 151 = 0.033522
第 4 組 katago 參數
nnCacheSizePowerOfTwo = 23
nnMaxBatchSize = 256
nnMutexPoolSizePowerOfTwo = 17
nnRandomize = true
numAnalysisThreads = 32
numSearchThreads = 1
gpu=”L4”
visits: 400 02:20 = 0.000222 x 140 = 0.03108
visits:1000 05:23 = 0.000222 x 323 = 0.071706
價錢考量
從一開始規劃的時候就想說要以盡量免費的方式去實作這整個功能,或是每個月不超過幾十塊台幣的預算來處理,以下逐筆來分析各個服務的價格,以及如果想要當個免費仔的話需要注意哪些點:
1. cloud run 價格
根據 Cloud Run 定價 的頁面每個月有一定的免費額度
CPU:每月前 180,000 vCPU-秒免費
RAM - 每月前 360,000 GiB-秒免費
要求:每月 200 萬次要求免費
根據我們這種休閒式的下棋法一個月肯定不會超出這個免費額度的用量,所以使用 cloud run 的價格可以說是免費
2. gcs (google cloud storage) 價格
Cloud Storage「一律免費」部分的用量限制 頁面有提到每個月有免費的 5GB 用量,但只限於 US-WEST1、US-CENTRAL1 和 US-EAST1 的地區,這裡我一開始犯了個錯,我把 gcs 的地區開在 asia-east1 台灣,這樣就沒有每月的 5GB 免費用量了,還好我後直接另開了一個新的在 us-east1 多賺這 5GB 的免費用量,但我算過將圖片、棋譜等存在 gcs 就算真的會被收到錢每個月應該也不會超過 10 塊台幣是非常可以接受的範圍,這裡有需要注意的一點是記得要在 gcs 的生命週期設定頁面中,新增 “刪除物件” 的動作,我預設是將下棋的圖片保留 30 天,過後就直接刪除,這樣應該就更可以保證價格不會太高
3. google artifact registry 價格
每次要部署 cloud run 時都需要將程式碼用 docker build 出來放置到 artifact registry 上面,根據 Artifact Registry 定價 的頁面,每個月 build 出來的 docker 在 0.5 GB 以下的話是免費的,而超過 0.5 GB 的話每 GB 就要收取 $0.1 美金,這其實是非常龐大的一筆支出,目前單次 build 出來的 docker 大約是 450MB 接近收費的上限,而且每次測試 debug 部署一次就會產生出新的 docker image 出來於是這筆費用其實非常可觀
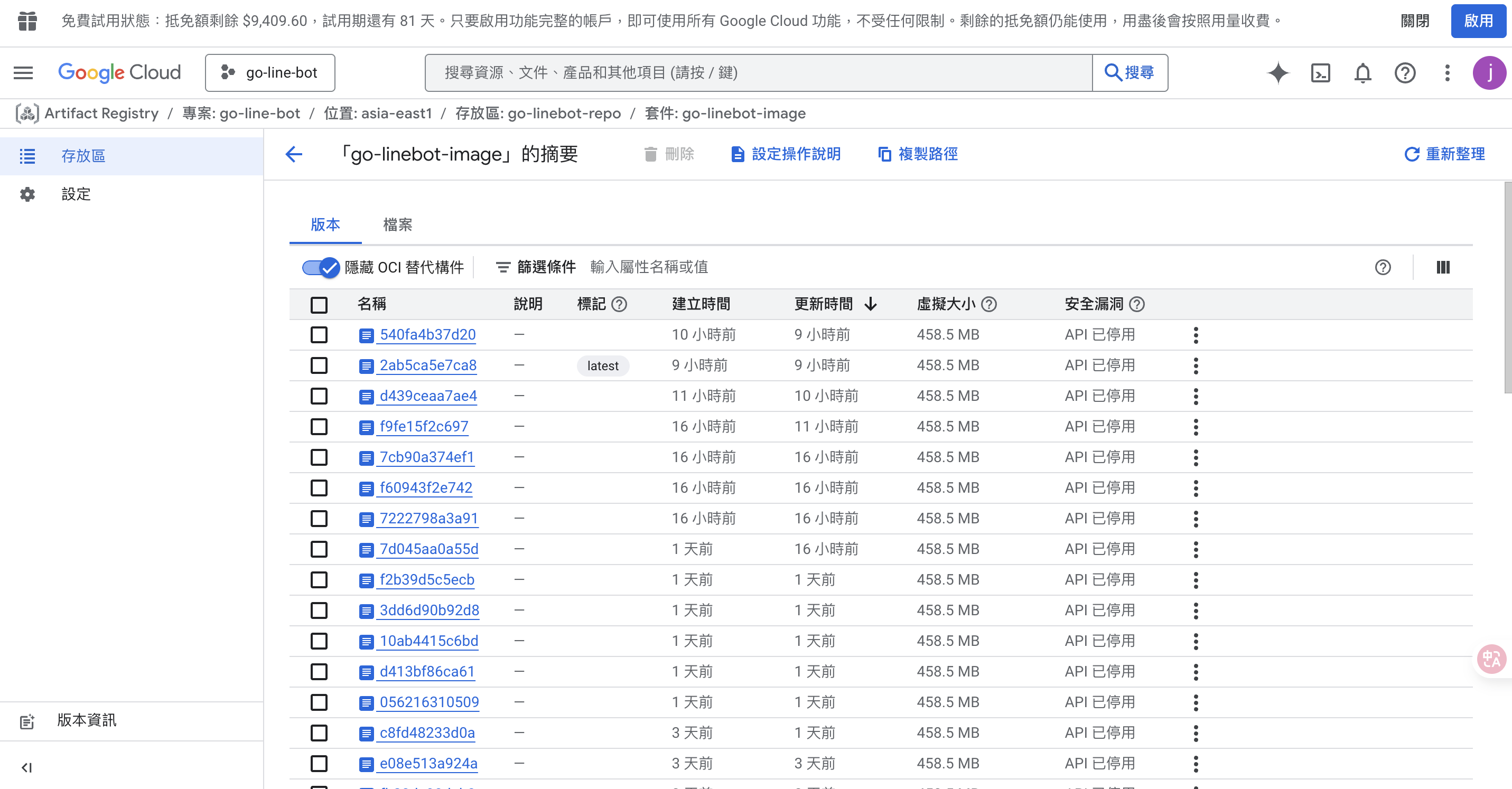
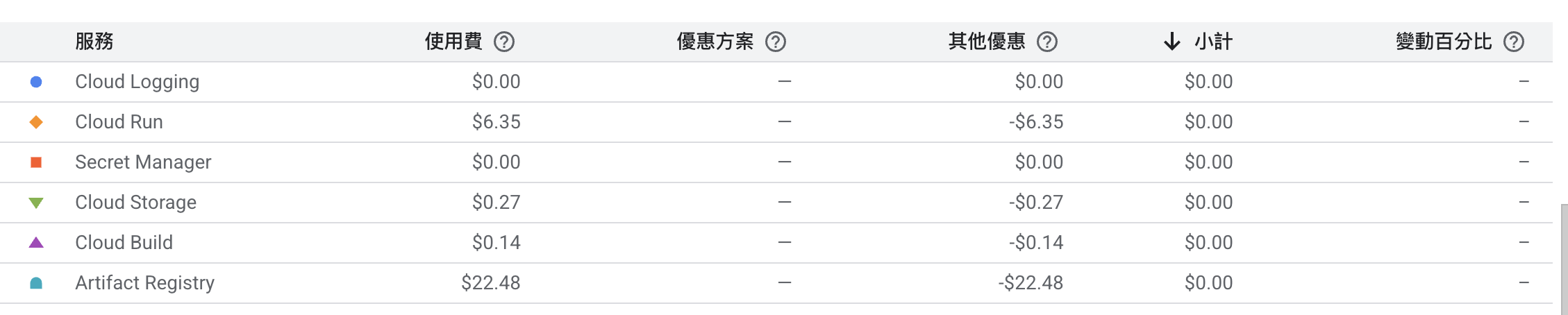
可以看到由於在開發測試的時候會不斷 build 出新的 image 上去,所以價錢竟然被收到了誇張的 $22.48 美金,這裡要注意的是一樣要像 gcs 那樣設定 image 自動刪除的機制 (資源清理政策),才不會一直放了一堆沒用到的 image 每個月被收那麼多錢
由於這是我第一次申請 gcp 的帳號,所以前三個月會給 $300 美金可以無限揮霍,實際上每個月會花到多少錢可能還是要等到三個月後再回來看看了
4. linebot 費用
linebot 傳送訊息分為兩種,一個是 reply message 另一個是 push message,reply message 是使用者傳送訊息後可以在一定時間內免費回覆訊息回去,而 push message 是主動推播機制,隨時可以由 linebot 傳送給使用者,而 linebot 每個月的免費方案 (輕用量) 是 200 則訊息,這 200 則訊息其實指的就是 push message,reply message 由於是即時回覆給使用者所以並不會被計算在內,所以像是使用者使用 “@NTUGoBot d4” 下棋後回傳棋盤圖片由於時間很短,可以發送免費的 reply message 回去,但請 katago 執行 AI 覆盤時因為時間太長,可能無法使用 reply message,所以這裡使用的是 push message,為了避免傳送 20 筆關鍵手數耗費到太多訊息數 (實際上計算訊息的次數是 20 x 群組人數),最終採用的是 flex carousel message 方案,每 10 筆關鍵手數為一組發送,這樣的話實際上會被計算的訊息次數就變成 2 x 群組人數,覆盤次數不多的話可以控制在每個月 200 則訊息內,但實際上發現如果真的用到每個月超出 200 則,其實只要額外再申請一個 linebot 就可以繞過這個限制
5. ChatGPT 費用
我覺得這是唯一會花到錢的地方,每執行一次 20 手的覆盤大概會花費 0.2 塊台幣,其實也是很少就 side project 的性質來說 cp 值很高
6. modal
modal starter 的免費方案每月就有 $30 塊美金的運算資源,每覆盤一局棋用到 L4 GPU 5 分鐘的運算資源大概也才花 $0.02 美金吧,所以目前倒是可以盡情揮霍一番

待實作功能
1. gcp cloud run 新增 worker
現在的流程是當 modal 執行完覆盤分析的結果會送一個 callback 到 cloud run 的 /callback/review 路由,接著畫出 20 筆關鍵手數圖以及呼叫 ChatGPT 產出每一手的評論,一開始採用的是 modal call /callback/review 路由時,直接回傳 response 200,之後再在背景起一個 task 去畫圖以及產出評論,但發現這樣的話有可能在兩三分鐘呼叫 ChatGPT 的過程中,cloud run 判斷已經沒有請求在運行,而直接把整個服務關閉掉,導致過一陣子 ChatGPT 回傳結果時 cloud run 已經關閉無法處理後續的畫圖跟產出評論,所以目前改成 /callback/review 路由會在畫圖及 call ChatGPT 的評論都完成並將覆盤回傳 line 後才 response 200,但這樣的缺點就是在 /callback/review 路由跑的兩、三分鐘時間內,modal 上的服務也都還開著會被以秒計費,浪費了很多 GPU 的運算時間,但在 modal 免費方案 $30/月的贈與下,這樣浪費時間一樣還不會超支就先不處理這塊了,不然正確的步驟應該是 /callback/review 路由接收到 katago 分析的結果後馬上 response 200,接著 call 另一個 worker 去呼叫 ChatGPT 產生評論,worker 產生評論完後再送一個 callback 到原先的 cloud run 統整所有東西回傳到 line 上面,如此一來就不會浪費 GPU 的運行時間,也可以維持服務的持續運作
2. 形勢判斷
(1/30 Done)
因應林老闆的願望,之後應該可以用 katago 做出當下的形勢判斷,畫出棋盤上哪些區塊是黑棋或白棋的領地,目前是哪一方領先幾目,在 katago 已經串接好 modal 的現在這功能應該很快能做出,但連續兩週都這麼晚睡實在太累了,只好先延遲這個功能
3. ai 對弈的等級
目前 ai 對弈是採用 katago 的 gtp_example.cfg 設定檔,這個設定檔似乎是理論上可以下出的最佳手,但缺點是 AI 分析了後續的所有棋步,所以跟 AI 對下可能會覺得不像在與真人對弈,他可能會時常手拔或覺得局面已經領先兩、三目了就故意放水,反正只要最後能贏 0.5 目都是贏,這種設定的模式不知道適不適合?所以後續有考慮是否可以採用 gtp_human9d_search_example.cfg 這個設定檔,把 katago 的棋力設定在職業九段的水準,這樣一來 ai 應該對於局部的下法都會回應,或許對我們想要研究局部的定石或是下法更有幫助?
4. 縮小 DockerFile 的大小
(1/30 Done)
目前部署到 cloud run 上的 docker file 大小是 463 MB,應該要使用 多階段建構 (Multi-stage Build),將編譯與執行階段拆開來,這樣最終部署上去的 docker image 就不會包括 gcc, g++ 這些臃腫的套件,但因為 artifact registry 的免費限制是 0.5 GB 的儲存空間用量,暫時應該不會多被收錢
改成多階段建構後縮小了大約 100 MB
結論
平常開發是利用每天晚上陪女兒睡覺睡到 11 點後再起來寫程式到一兩點這短暫時間,過了這種生活兩個多禮拜的時間實在很累,但能夠藉由這次機會嘗試 gcp 雲端服務與 modal ai 服務的串接蠻有成就感的,最終做出來的成果在 line 中下一手棋接著等待幾秒後 ai 回應下一手,這種下棋的體驗還蠻酷的,總之靠著這時代 AI 的強大邊做邊學才能讓我完成這個小遊戲,並且享受跟大家一起在群組中下棋與說垃圾話的樂趣,這半個月做出這個有趣的東西真是蠻值得的